

포브스, 기자 위한 유료 뉴스레터 자체 플랫폼 개발 왜? | 미디어고토사+ 뉴스레터 | Vol.4
포브스, 기자 위한 유료 뉴스레터 자체 플랫폼 개발 왜? | 미디어고토사+ 뉴스레터 | Vol.4
이번주 미디어고토사+도 저널리즘, 미디어 기술, 미디어 비즈니스 3개 주제로 나누어 작성해봤습니다. 이런 구분법에 대해선 어떻게 생각하세요? 아무래도 미디어고토사+를 구독하시는 분들의 관심사가 다들 나뉘어져 있다 보니 100%까지는 아니더라도 50% 가까이는 충족시켜 드려야 하지 않을까 생각을 했습니다. 더 좋은 개선안이 있다면 얼마든지 메일을 보내주세요. 항상 기다리고 있습니다.
저널리즘
트럼프 이후 ‘거대한 거짓말’을 넘어설 수 있는 3가지 방법
워싱턴포스트 칼럼니스트 매거릿 설리반의 칼럼에서 가져왔습니다.
어떤 소식이냐면요 : 아시다시피 트럼프 시대는 저널리즘의 상식적 관행이 시점에 따라 위험해질 수 있음을 증명해줬습니다. 이러한 현상에 저널리즘을 무엇에 주의를 더욱 기울여야 할지를 제안하고 있는데요. 주로 로젠스틸의 이야기를 근거로 제시합니다. 그 세가지는 속기 즉 받아쓰기에 의존하지 말 것(Stop relying on shorthand), 정직한 리트머스 테스트를 활용할 것(Use an honesty litmus test.), 사람들이 진실한 정보를 흡수하는 방법에 대한 과학을 배울 것(Learn the science about how people absorb truthful information) 등이었습니다.
조금더 자세히 설명을 드리면 : 첫번째부터 설명을 하자면, 근거 없는 주장(baseless claim), 근거 없음(without evidence)이라는 문장을 넣어서 보도를 하곤 하는데요. 이게 그렇게 효과가 없다는 것입니다. 대안은 왜 근거가 없고 어떻게 틀렸는가가 증명됐는지를 더 설명해야 한다는 것이죠. 비록 짧은 리포트라도 다소 시간을 가지고 이러한 부가 설명을 더 넣어야 한다고 강조합니다.
두번째 정직한 리트머스 시험지의 활용은, 기자들의 오랜 관행 즉 양쪽 편의 이야기를 모두 인용하는 것을 미덕으로 삼아왔는데요, 이 방식에서 벗어나야 한다는 것이죠. 악의적 거짓말에 동등한 시간과 분량을 제공하는 것은 완전히 파괴적인 관행이라고 말하고 있습니다. 거짓에 메가폰을 쥐어주어서는 안된다는 의미죠. 정직의 리트머스를 통과한 발언들이 양쪽 사이드에 배치돼야 한다는 것입니다. 세번째 로젠스틸의 이 말이 핵심이긴 하겠네요. "합리적이지만 회의적인 수용자를, 그들의 수용성을 높이는 신경 과학을 기자들이 이해해야 합니다."
미디어 기술
뉴욕타임스의 기사 추천 모델은 어떻게 개발되고 있을까

어떤 내용이냐면요 : 뉴욕타임스는 보다 포괄적인 개인화 추천 알고리즘을 만들어내기 위해 머신러닝 모델의 도움을 빌리고 있다는 내용입니다. 이 글에선 기사 추천 모델을 뉴욕타임스가 어떻게 개선시켜 가는지 그 과정들을 설명하고 있는데요. 가장 보편적인 LDA 모델(잠재 딜리클레 할당)에 키워드 기반 벡터, '일반 문장 인코더'를 결합해서 분류표를 생성하는 작업을 한다는 거죠. 1차로 위키피디아 데이터를 학습시킨 뒤 뉴욕타임스 170년 기사를 재학습 시켜서 모델링을 한다는 내용입니다.
이게 왜 중요하냐면요 : 이 한 문장 때문입니다. “우리 모델이 여러면에서 기존 쿼리 기반 시스템을 능가한다 하더라도 사람의 감독없이 수용자들의 관심사를 선별하는 것은 무책임하다는 것을 깨달았습니다.” 이를 Human in the Loop라는 표현과 개념으로 압축했습니다.
사실 뉴욕타임스는 기사 자체의 태그뿐 아니라 사용자 관심사와 매칭시킬 수 있는 별도의 라벨을 모든 기사에 부착해왔던 모양입니다. 문제는 사람이 작성한 라벨은 부정확한 경우가 적지 않아서, 이를 바로잡는 게 필요했습니다. 이를 모두 사람이 한다면 어마어머한 일이 되겠죠? 이를 기계학습을 통해서 다시 채워가는 방법을 쓴 것입니다.
대체로 괜찮은 결과를 뽑아내긴 했지만 모든 게 완벽할 순 없었던 모양입니다. 그래서 사람의 감시와 검토가 필요했다고 설명을 하고 있고요. 이를 통해 알 수 있었던 것은, 기사 추천을 위해 기존에 가지고 있는 기사 내 태그 데이터, 그것의 계층적 연결 구조, 또 관심사와 매칭시킬 수 있는 추가적인 라벨까지 다양한 데이터들이 하나의 기사를 감싸고 있다는 사실이었습니다. 태그와 같은 데이터 관리, 그것의 가이드라인이 이렇게나 중요한 모양입니다.
미디어 비즈니스
포브스, 기자들을 위한 유료 뉴스레터 자체 플랫폼 론칭

어떤 소식이냐면요 : 서브스택(Substack) 다들 잘 아시죠? 요즘 워낙 잘 나가는 유료 지원 뉴스레터 플랫폼이라 모르는 분이 많지는 않을 것 같습니다. 포브스가 이와 유사한 자신들만의 플랫폼을 개발해 곧 론칭한다고 합니다. 일단 그들 기자들에게 제안을 하고, 향후 포브스 기고자 네트워크에도 적용을 할 계획이라고 밝혔습니다. 현재 포브스가 관리하고 있는 기고자 네트워크는 약 2800명 수준. 절반만 이 대열에 동참해도 1400개의 뉴스레터 채널이 만들어지는 셈입니다. 아주 빠르게 성장을 시킬 수 있는 네트워크를 보유한 셈이죠. 자사 기자들이 유료 뉴스레터를 운영하게 될 경우 그 수익의 50%를 회사와 나누고, 광고 수익도 일부 쉐어하는 모델이라는 게 엑시오스의 설명입니다.
우리가 얻을 교훈들 : 혹 그거 아시나요? 뉴스레터 이용자의 유료 전환율은 5~10%에 이를 만큼 높은 편입니다. Paywall 운영 시 통상적인 전환율이 3%인 것과 비교하면 상대적으로 높은 수치입니다. 뉴스레터는 그만큼 충성도가 높은 독자들이 참여하게 되는 채널이라는 이야기입니다. 수용자 수익 모델을 운영하고 있는 언론사들이라면 뉴스레터의 높은 전환율에 주목을 하기 마련이죠. 하지만 외부 플랫폼에 전적으로 의탁하는 것은 여러 고민을 안겨줍니다.
수익 배분의 문제, 경험의 체득, 데이터 의존성 등등 말이죠. 여력이 된다면 직접 개발에 나서는 것도 방법일 겁니다. 사실 우리는 포브스가 처음이라고 생각할지는 모르겠지만, 팻치라는 언론사도 자체 뉴스레터 플랫폼 ‘팻치 랩’ 을 개발해 운영하고 있습니다. 플랫폼 의존성에서 탈피하려는 조류와 언론 산업의 침체 이후 독립 언론인으로 살아가려는 흐름 등이 결합한 결과가 아닐까 싶습니다. 어떠세요 여러분들도 독립 기자로 살아볼 의향이 있으신가요? 이 주제는 별도로 글로 정리를 해보도록 하겠습니다.
미디어도서관에 업데이트 된 자료들
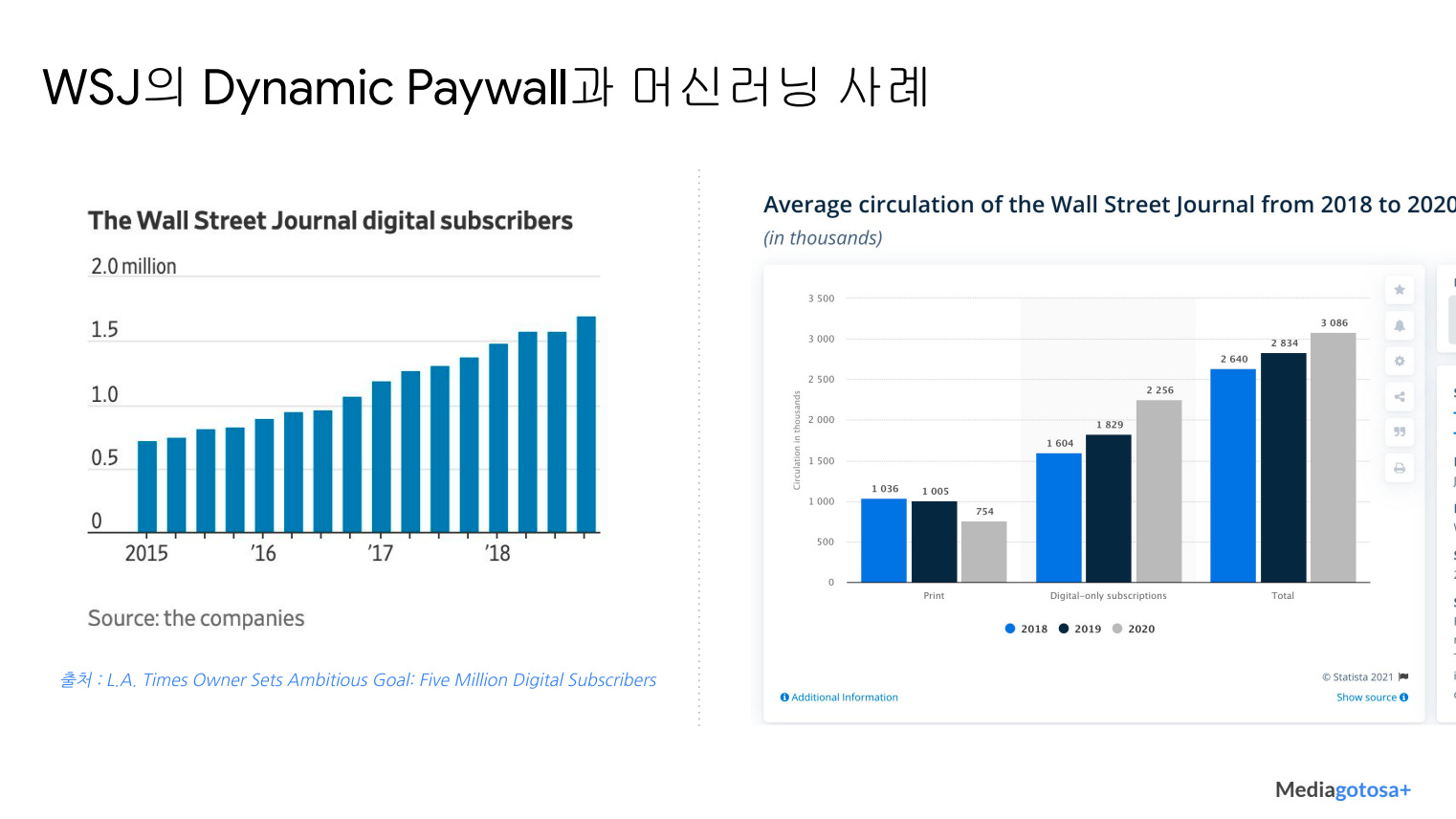
[커피타임] Paywall의 종류와 머신러닝 : 지난주 금요일 커피타임에서 발표했던 자료입니다. 페이월의 종류와 머신러닝의 개입 방식, 그 사례로서 월스트리트저널에 대한 소개 등이 담겨 있습니다. 유익할지는 모르겠지만 필요하신 분들에겐 조금이라도 도움이 됐으면 하는 바람입니다.
공지
커피타임 시간이 벌써 돌아오네요. 다음주 목요일과 금요일 중 하루를 예상하고 있습니다. 가급적 이번에는 금요일보단 목요일에 진행해볼까 고민 중입니다. 이에 대한 의견도 보내주시면 감사하겠습니다. 확정되는 대로 다시 알려드리도록 할게요.